
खुलासा: This article was written with AI assistance and reviewed by EmpirioLabs AI.
EmpirioLabs runs more than 100 AI models on one API, from every major lab and a long list of newer ones. That makes the platform a useful vantage point on a simple question: with the whole field available on one bill and no lock-in, which models do developers actually choose?
We looked at real usage across the platform to find out. The answer is consistent, and in one respect genuinely surprising. Developers are converging on a small set of fast, capable models from a new generation of labs, and they are choosing them on merit rather than reaching for the biggest brand name.
A note on method: every figure below is drawn from real, aggregated platform traffic and is shown as a percentage. Where we discuss preference, we normalize usage against how many models each maker offers, so the numbers reflect what developers choose, not simply what happens to be on the shelf.
With 100+ models to choose from, usage lands on a few
The first pattern in the data is concentration. Developers have an enormous menu in front of them, but they do not spread across it. Of the models that actually saw use, the three most popular account for 40% of all language requests, and the top ten account for nearly nine in ten. The long tail of models exists and gets some use, but it carries a small share of real work.

This concentration matters more than it first appears. It means a handful of models are quietly setting the baseline for what developers expect on quality, speed, and price. A new model does not compete against the whole field. It competes against the short list at the top, and if it cannot beat those models on a real task, it stays in the tail regardless of how it benchmarks on paper.
The most-used models
Ranked by share of all language usage, no single model runs away with it. Z.ai's GLM models, MiniMax M3, Xiaomi's MiMo, and DeepSeek's fast models cluster at the top, each taking a similar slice, while the rest of the catalog fills in a long tail. This is a competitive top group rather than one dominant winner, which is healthy: it means developers are actively comparing options instead of defaulting to a single default.
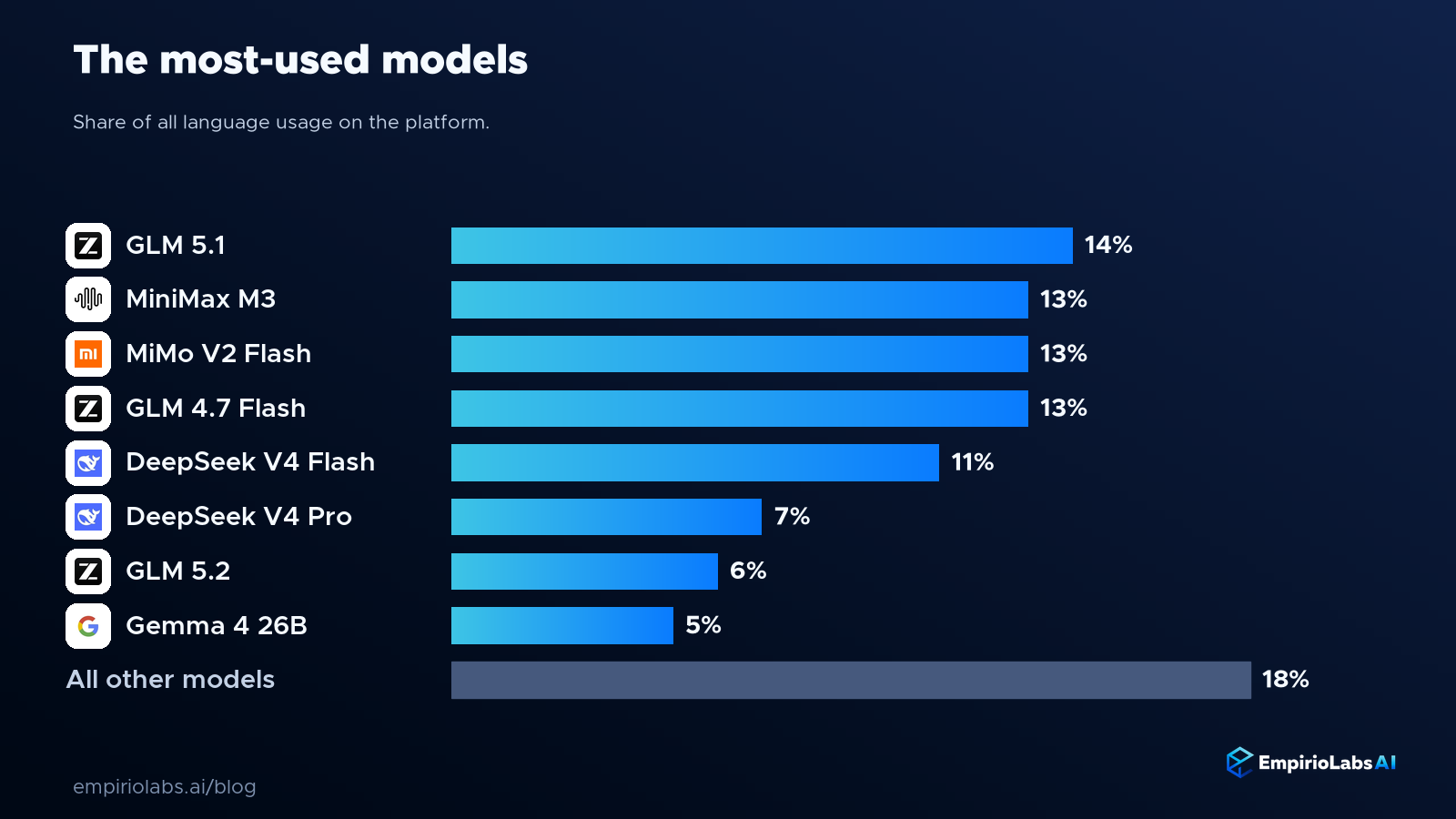
Raw usage like this is only one lens on the question. It tells you where the request volume goes, which is useful, but volume can be concentrated in a handful of heavy users and it does not reveal how broadly a model is adopted. For that, we look next at how many separate developers pick each maker, which is a more democratic view of what people actually choose.
This is preference, not just availability
It is fair to push back on a popularity ranking. If a catalog leans a certain way, usage will tend to follow, so a list of popular models can simply reflect what a platform decided to stock. To separate genuine preference from availability, we compared each maker's share of usage against its share of the catalog.
The gap between the two is the real signal, and it is striking. Z.ai makes up a small fraction of the available models yet takes the single largest share of usage. DeepSeek, Moonshot, and Xiaomi all draw far more usage than their footprint in the catalog would predict. At the same time, the maker with by far the most models available, Alibaba, sees only a modest share of usage, and a well-stocked lineup from Amazon is barely touched.
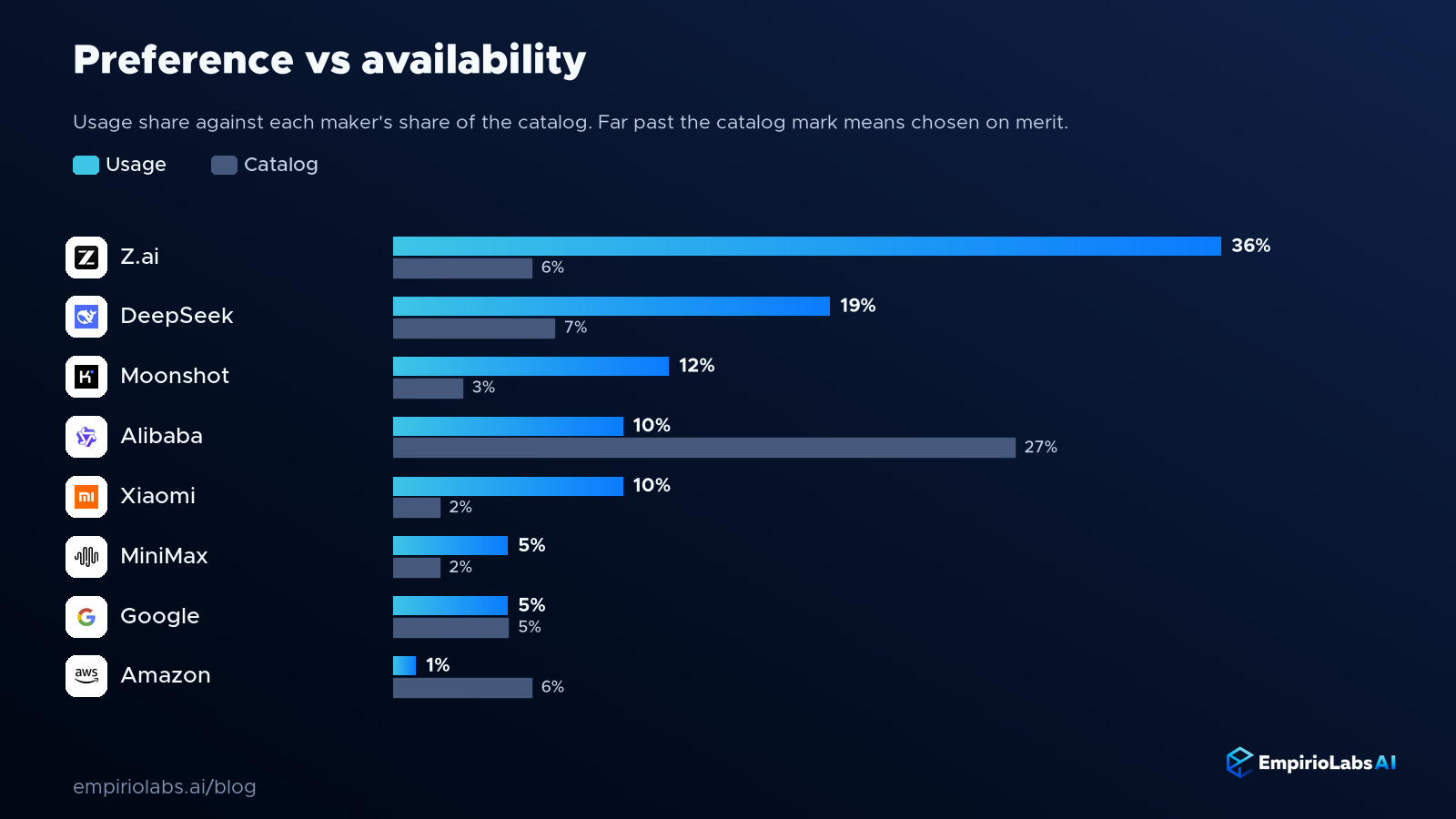
In other words, developers are not simply using what is placed in front of them. They are actively reaching for a specific set of models and passing over others that are equally available and, in some cases, far more numerous. Availability is not destiny. A large catalog presence does not translate into usage unless the models earn it on real work, and that is the finding every model lab should sit with.
A small group of labs owns demand
That more democratic view, counting how many developers pick each maker as their default rather than counting raw request volume, concentrates demand into a short list. Z.ai leads by a clear margin, followed by DeepSeek and Moonshot, with Alibaba, Xiaomi, and MiniMax close behind. Everyone else combined is a small remainder.
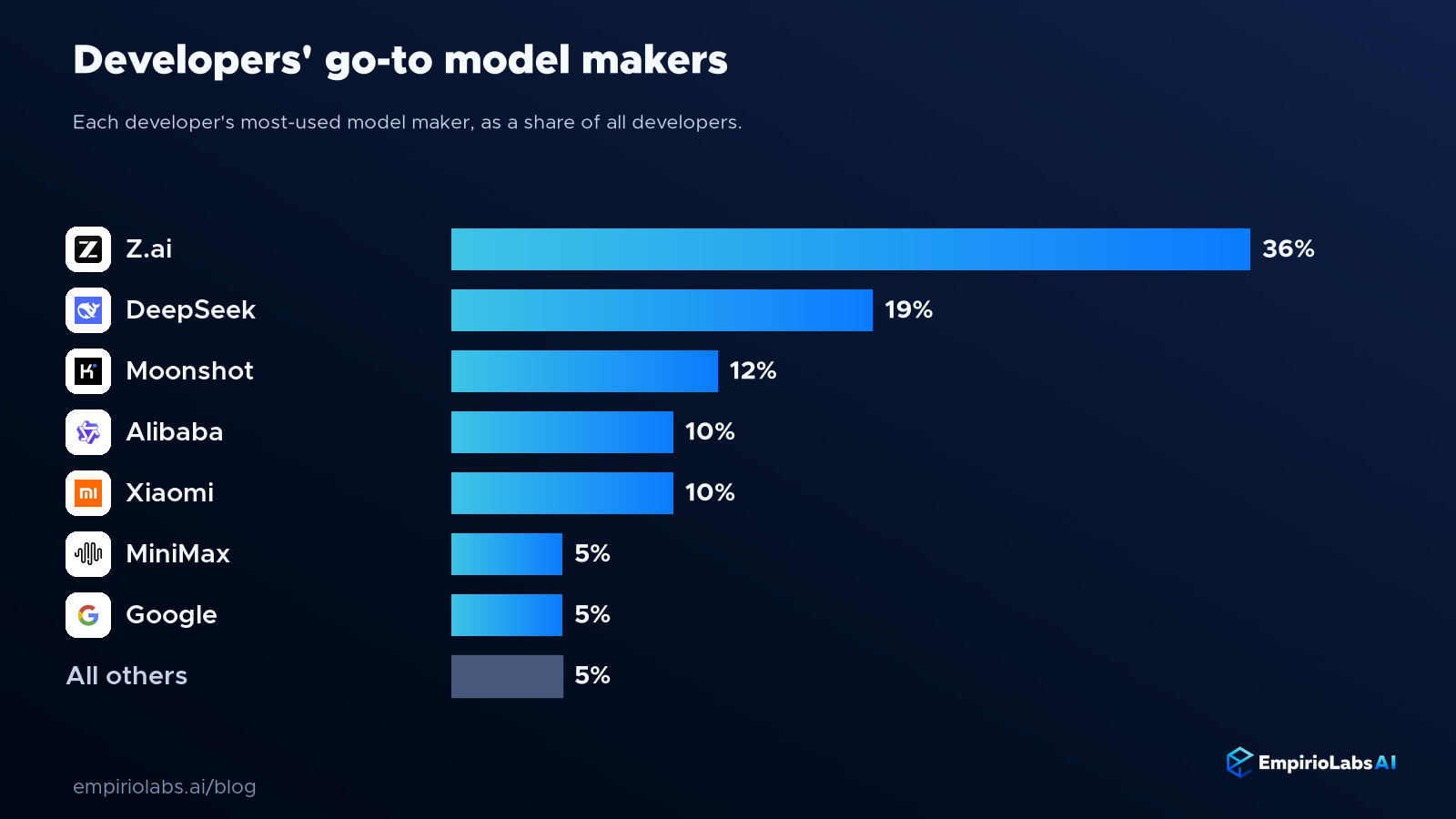
What unites the leaders is not a marketing budget or a household name. It is a willingness to ship strong, openly available models at a fast pace. The labs winning developer attention are, for the most part, the ones releasing capable models that teams can inspect, adapt, and run cheaply, and they are iterating quickly enough to stay on the short list as expectations rise.
Speed beats size
There is a common assumption that developers reach for the biggest, smartest model they can afford. The usage data says otherwise. We split the models into two groups: lightweight variants, meaning the Flash, Mini, and Lite versions built for speed and low cost, and full-size models. The majority of language requests go to the lightweight variants.

This is a rational response to how real applications work. Most production tasks, such as classification, extraction, routing, summarization, and short generation, do not need a frontier model, and a fast, inexpensive model that answers in a fraction of the time is the better engineering choice. The larger models are held in reserve for the genuinely hard problems, not reached for by default. For teams watching both their latency budgets and their bills, that instinct is worth trusting.
Beyond text: what developers generate
Usage is not only about language. Turning to media generation, the patterns are just as concentrated as they are for text. Image generation runs almost entirely through a single model. Video is split mainly between Kling and Seedance. Audio work, notably, is dominated by transcription rather than synthesis, which says something about how teams use audio models today: more to understand existing sound than to create new sound.
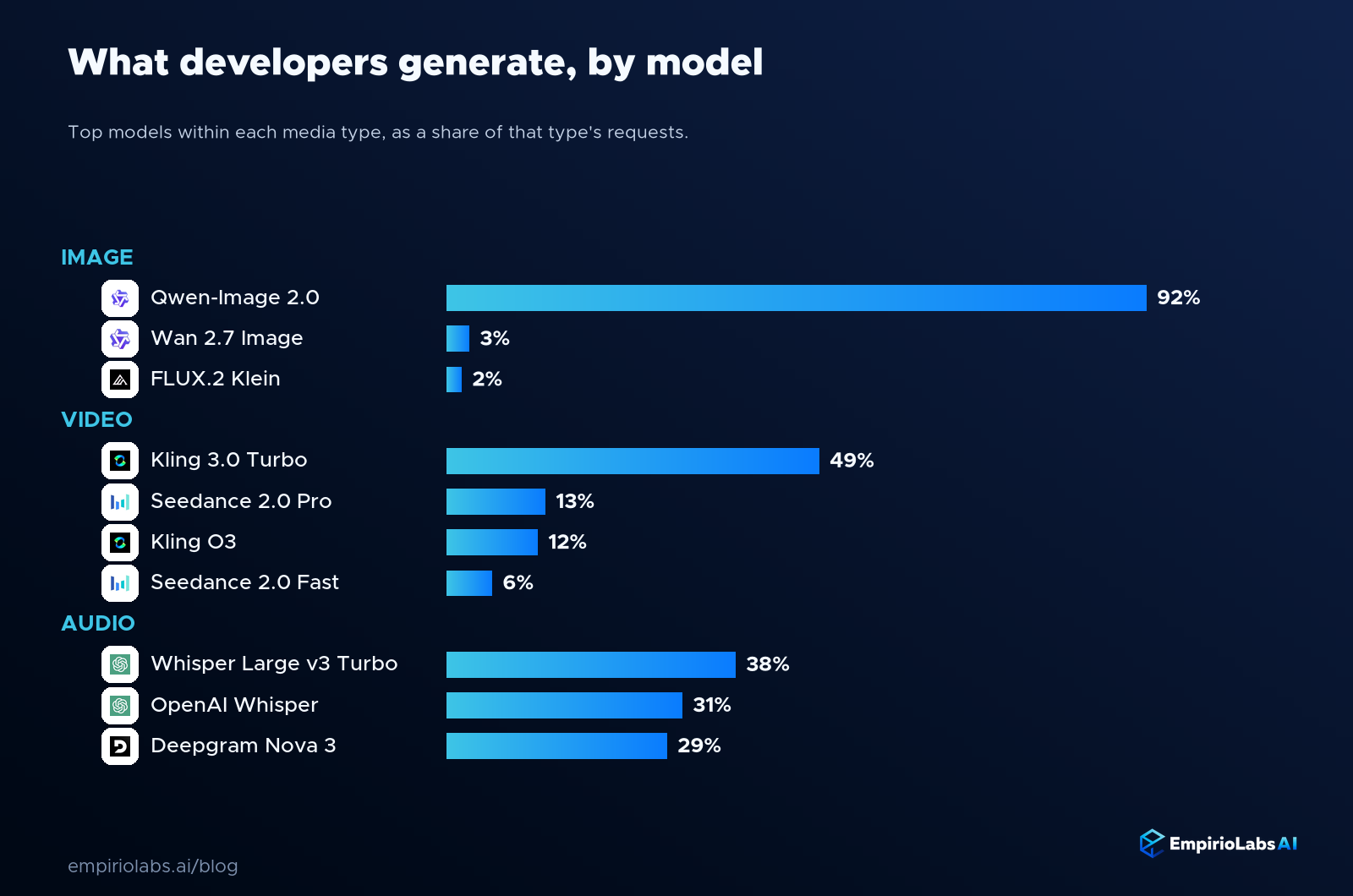
The same rule holds across every modality. A short list of models does the overwhelming majority of the work, and the rest of the field competes for what is left.
What this means if you are choosing a model
The practical lesson running through all of this is to choose per task, not per brand. The most-used models on the platform are not the most famous ones. They are the ones that win a real evaluation on cost, speed, and quality for a specific job. A few habits follow directly from the data:
- Start with a fast, lightweight tier and only move up if the task genuinely needs a larger model. Most work does not.
- Evaluate open-weight models seriously. On real usage they are not a compromise choice, they are the default choice for production work.
- Do not assume the biggest catalog name is the best fit. Availability and quality are different things, and the usage data shows developers treating them that way.
- Re-check your defaults regularly. With the top of the field this competitive, the best model for a task can change from one quarter to the next.
The takeaway
The story of real AI usage in 2026 is convergence and choice. Developers have more models available than ever, and they respond by concentrating on a small set of fast, capable models from a new generation of labs. Most importantly, they choose those models on merit, not because of what a platform happens to offer. The biggest catalog presence does not win. The best model for the job does, and increasingly that model is open, fast, and inexpensive.
You can compare every model, modality, and live price across the full catalog on the EmpirioLabs models page.


