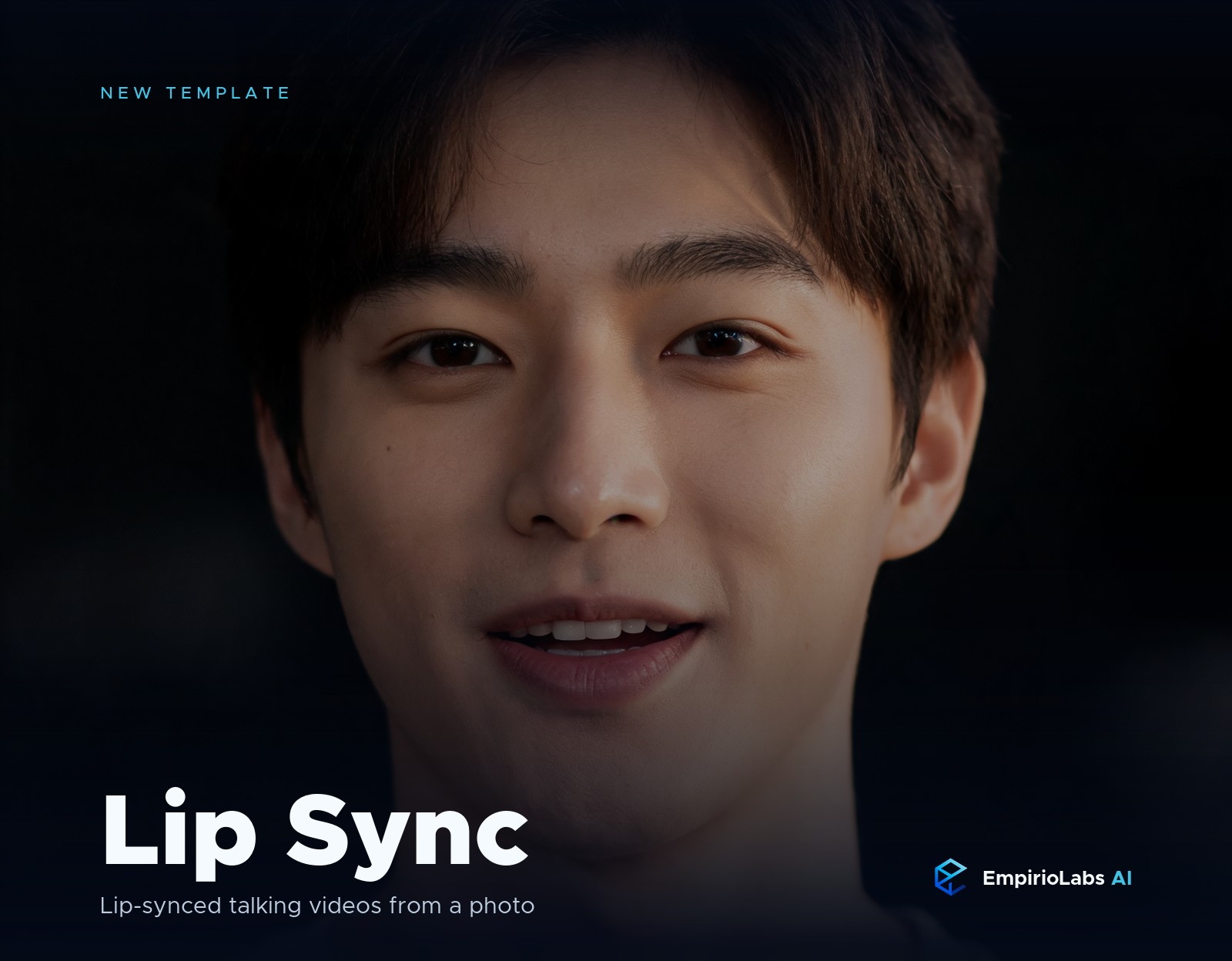
Synchronisation des lèvres transforme un portrait en une vidéo parlante. Vous lui donnez une photo d'un visage et d'un clip audio, et le visage parle ou chante dans le temps avec le son, avec des formes de bouche correspondantes, des micro-expressions naturelles, et un regard régulier. C'est le moyen le plus rapide de mettre des mots dans la bouche de quelqu'un pour un expliquateur, une voix off, un extrait de musique, ou un avatar parlant.
Le modèle Lip Sync sur EmpirioLabs le fait à partir d'un portrait et d'un clip vocal. Télécharger une photo claire face à l'avant et l'audio que vous voulez qu'il le dise, et le modèle rend une vidéo en tête de conversation où les lèvres suivent le son. Il n'y a aucune invitation à écrire. La génération prend environ 60 à 180 secondes.
Voir en action
Voici un échantillon généré entièrement par le modèle Lip Sync sur EmpirioLabs, à partir d'un portrait synthétique et d'un court clip vocal.
Ce dont vous avez besoin
Deux choses. Un portrait clair, orienté vers l'avant, avec une face bien éclairée à peu près centrée, fonctionne mieux. Et une voix ou un clip en mp3 ou en wav. Le visage parle à tout ce que dit l'audio, donc un enregistrement propre avec peu de bruit de fond donne le résultat le plus net. La vidéo finie correspond automatiquement à la longueur de votre audio, jusqu'à 15 secondes.
Comment faire des vidéos de synchronisation de lèvres sur EmpirioLabs
Vous avez besoin d'un compte EmpirioLabs avec des crédits actifs.
Étape 1: Ouvrez le terrain de jeu
Connexion à plate-forme.empiriolabs.ai et cliquez sur Terrain de jeu dans la navigation supérieure. Le modèle Lip Sync recommande Wan 2.7 et le sélectionne pour vous.
Étape 2: Ouvrez le sélecteur de modèles
Cliquez sur le Modèles bouton dans le coin supérieur gauche du terrain de jeu. Chaque effet créatif s'ouvre dans un modal. Filtrer par le Portrait catégorie pour trouver Lip Sync rapidement, ou tapez le nom dans la barre de recherche.
Étape 3: Ajouter une photo du visage et un clip vocal
Cliquez sur la carte Lip Sync pour l'appliquer. Le compositeur demande ensuite deux téléchargements: d'abord une photo de visage, puis une voix ou un clip audio. Ajoutez les deux, et le bouton Générer s'allume. Il n'y a pas d'invite de texte, car l'audio est le script.
Étape 4: Générer
Affichage Générer. Les sondages de terrain pour le résultat. Le clip en tête de conversation atterrit en ligne avec un bouton de téléchargement et un lien partagé de 7 jours. Échanger l'audio pour faire le même visage dire quelque chose de nouveau, ou échanger la photo pour donner à la même voix un visage différent.
Utilisation du modèle Lip Sync via l'API
Le même effet vient de tout client compatible OpenAI. Passer modèle: "lip-sync" sur une norme POSTE /v1/videos/generations appel avec un image et une audio URL. EmpirioLabs choisit le modèle recommandé et applique l'effet:
https://api.empiriolabs.ai/v1/videos/generations \ -H "Autorisation: porteur $EMPIRIOLABS API KEY" \ -H "Type de contenu: application/json " \ -d '{"template": "lip-sync", "image": " https://your-portrait.jpg", "audio": " https://your-voice.mp3"}'Le paramètre renvoie a aide-emploi immédiatement et pouvoir vous pouvez frapper jusqu'à ce que la vidéo soit prête. La pleine demande et la forme de réponse vivent dans le Modèles de génération docs.
Prix
Les factures Lip Sync par seconde de la vidéo générée au taux standard du modèle recommandé, donc un court clip ne coûte que quelques cents. Vous ne payez que pour des générations réussies, de sorte que les emplois échoués ou refusés ne sont pas facturés. Le prix total pour chaque modèle vit sur le public page de prix.
Essayez Lip Sync maintenant
Le modèle Lip Sync est en direct pour chaque client EmpirioLabs. Signer à plate-forme.empiriolabs.ai, ouvre le terrain de jeu, et envoie ta première tête de conversation dans quelques minutes. Si vous voulez le construire dans un produit, le même effet s'exécute à partir de l'API avec un seul champ sur un appel de génération vidéo standard.
Parcourir tous les modèles - Oui Ouvrez le terrain de jeux - Oui Lire les modèles de génération docs