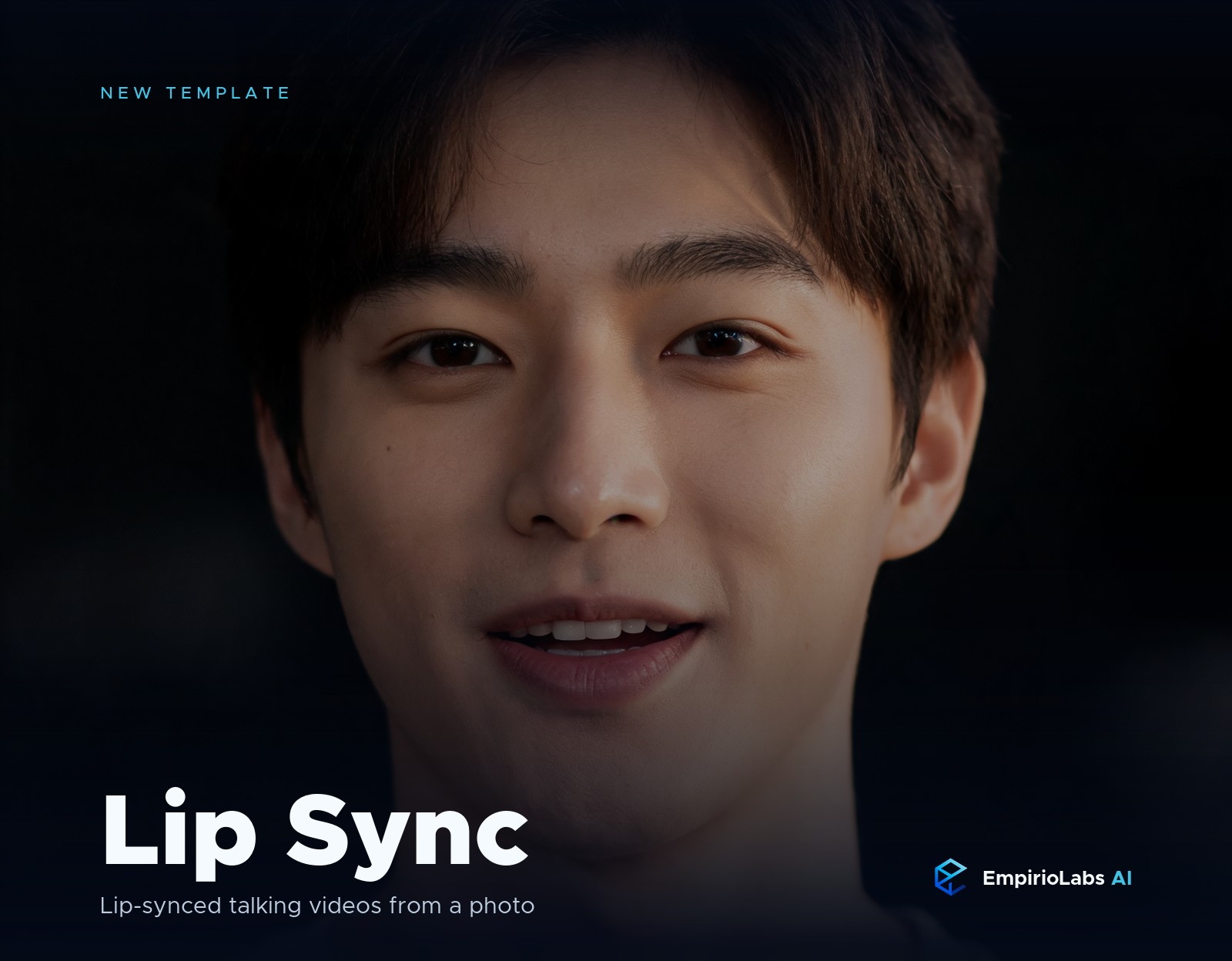
Lip sync turns a still portrait into a talking video. You give it one photo of a face and an audio clip, and the face speaks or sings in time with the sound, with matching mouth shapes, natural micro-expressions, and a steady gaze. It is the fastest way to put words in anyone's mouth for an explainer, a character voiceover, a music snippet, or a talking avatar.
The Lip Sync template on EmpirioLabs does this from one portrait and one voice clip. Upload a clear front-facing photo and the audio you want it to say, and the model renders a talking-head video where the lips follow the sound. There is no prompt to write. Generation takes about 60 to 180 seconds.
See it in action
Here is a sample generated entirely through the Lip Sync template on EmpirioLabs, from one synthetic portrait and a short voice clip.
What you need
Two things. A clear, front-facing portrait, with one well-lit face roughly centered, works best. And a voice or singing clip in mp3 or wav. The face talks to whatever the audio says, so a clean recording with little background noise gives the sharpest result. The finished video automatically matches the length of your audio, up to 15 seconds.
How to make lip sync videos on EmpirioLabs
You need an EmpirioLabs account with active credits.
Step 1: Open the playground
Sign in to platform.empiriolabs.ai and click Playground in the top navigation. The Lip Sync template recommends Wan 2.7 and selects it for you.
Step 2: Open the Templates picker
Click the Templates button in the upper-left corner of the playground. Every creative effect opens in a modal. Filter by the Portrait category to find Lip Sync fast, or type the name in the search bar.
Step 3: Add a face photo and a voice clip
Click the Lip Sync card to apply it. The composer then asks for two uploads: first a face photo, then a voice or audio clip. Add both, and the Generate button turns on. There is no text prompt, because the audio is the script.
Step 4: Generate
Hit Generate. The playground polls for the result. The talking-head clip lands inline with a download button and a 7-day shareable link. Swap the audio to make the same face say something new, or swap the photo to give the same voice a different face.
Using the Lip Sync template via the API
The same effect runs from any OpenAI-compatible client. Pass template: "lip-sync" on a standard POST /v1/videos/generations call with an image and an audio URL. EmpirioLabs picks the recommended model and applies the effect:
curl https://api.empiriolabs.ai/v1/videos/generations \
-H "Authorization: Bearer $EMPIRIOLABS_API_KEY" \
-H "Content-Type: application/json" \
-d '{"template": "lip-sync", "image": "https://your-portrait.jpg", "audio": "https://your-voice.mp3"}'The endpoint returns a job_id immediately and a poll_url you can hit until the video is ready. The full request and response shape lives in the Generation Templates docs.
Pricing
Lip Sync bills per second of generated video at the recommended model's standard video rate, so a short clip costs only a few cents. You only pay for successful generations, so failed or refused jobs are not billed. Full pricing for every model lives on the public pricing page.
Try Lip Sync now
The Lip Sync template is live for every EmpirioLabs customer. Sign in at platform.empiriolabs.ai, open the playground, and ship your first talking-head in a couple of minutes. If you want to build it into a product, the same effect runs from the API with a single field on a standard video-generation call.
Browse all templates | Open the playground | Read the Generation Templates docs